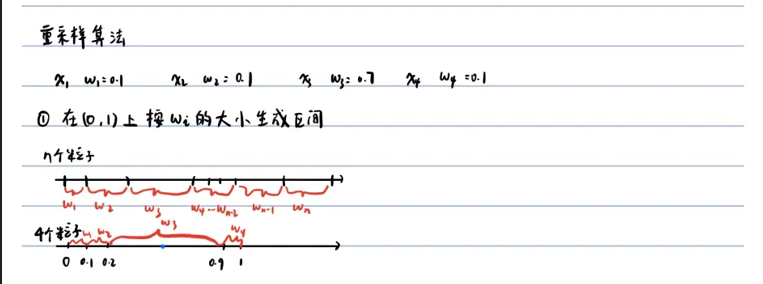
%生成c,范围为(0~1) c=zeros(1,n); c(1)=w(1); forj=2:n c(j)=c(j-1)+w(j); end %转盘子,生成随机数,看落在哪个区间 %首先我们要重采样n个粒子,粒子数要与之前相同 forj=1:n a=unifrnd(0,1);%均匀分布随机数 for k=1:n if (a<c(k)) xnew(j)=xold(k); break;%%%%一定要break,否则重采样粒子会被最后一个粒子覆盖,具体见新的第十讲 end end end %重采样完毕 %把新的粒子赋值给xold,为下一步递推做准备 xold=xnew; %所有粒子权重都设为1/n forj=1:n w(j)=1/n; end %把每一步的后验概率期望赋值给xplus xplus(i)=sum(xnew)/n; end plot(t,x,'r',t,xplus,'b','LineWidth',1) %y=x^2+R 似然概率是一个多峰分布,y=4,x=2或-2 %非线性问题一步一个坑,处处是雷 %如果问题本身的性质就是强烈的非线性,比如多峰分布这种,粒子滤波并不能化腐朽为神奇 %尽量不要有多峰分布 %粒子滤波的计算速度是大硬伤 %可以尝试没有重采样的粒子滤波代码会是什么样的,自己尝试写写,自己调调参数 %主要需要调Q,R,重采样,粒子数目